[译]5个能让Go更快的技巧
原文链接:Five that make Go Fast by Dave Cheney
Why Choose Go
Why are people choosing to use Go?
当人们谈论他们为什么决定学习Go,或在项目中使用Go时,他们会给出各种各样的答案。但是排在前三的几乎总是那几个:
- 并发(Concurrency)
- 容易部署(Ease of deployment)
- 高性能(Performance)
Concurrency
Go的并发原语对于使用单线程脚本语言(如Nodejs,Ruby或Python等),或拥有重量级Thread模型的C++,Java语言的程序猿是相当有吸引力的。
Ease of deployment
到目前,我们听到几乎所有的有经验的Go程序猿都非常欣赏Go程序部署的简洁性。
Performance
我相信“快”是大家选择Go的一个重要原因。
这篇文章中,我将与大家一起讨论造就了Go的性能的5个特性,以及Go如何实现这些特性的细节。
一 Values
我想讨论的第一个特征就是Go如果高效的处理和存储Values
Go
var gocon int32 = 2014
这个示例声明了一个Go int32变量,当编译的时候gocon占用了4个字节的内存。让我们把Go的变量值和其他语言做一个对比。
Python
>>> from sys import getsizeof
>>> gocon = 2014
>>> getsizeof(gocon)
24
由于Python表示变量的方式,存储一个Go中同样的int32值实际会占用6倍的内存空间。多余的空间将被Python用于追踪数据类型,以及引用计数等。
Java
int gocon = 2014;
//16 bytes on 32 bit JVM
//24 bytes on 64 bit JVM
Integer gocon = new Integer(2014)
类似于GO,Java中int32数据类型也只占用4个字节用于存储数据值。但是在一个集合,如list,map中使用这个值的时候,编译器必须将它转换成一个integer对象。所以Java中一个integer看起来更像上面代码的下面部分,实际占用的内存空间在16字节或24字节。
这个很重要吗?内存不是便宜又多么,为什么还要关注这些开销?
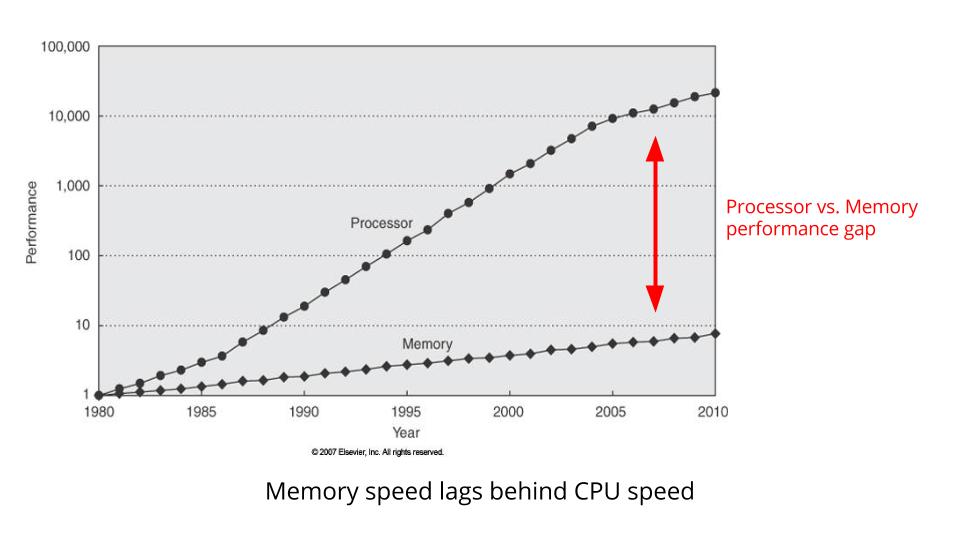
这张图显示了CPU速度与Memory速度之间的对比。注意,CPU时钟速度与Memory总线速度之间的差距越来越大。两者之间的差距就是效率,就是CPU需要花多少时间去等Memory。
直到1960’s年代,CPU的设计者才意识到这个问题。他们的解决方案就是加cache,在CPU和Memory之间插入一块小的但是更快存储。
让我们来看下如下的示例:
//location is a point in a 3 dimensional space
type Location struct {
//8 bytes per float64
//24 bytes in total
X, Y, Z float64,
}
//locations consumes 24 * 1000 bytes
var locations [1000]Location
Location类型用于表示3D空间内一些对象的位置。在Go里面每一个Location占用24个字节的空间。然后我们用这个类型构造了一个含有1000个Location的数组。它总的需要消耗24000字节的内存空间。不像指针数组指向1000个随机存储的数据结构,在数组中这24000字节是连续存储的。**这点非常重要,因为现在这1000个Location数据结构可以被紧凑的打包在一起,连续的存放在cache里。
- Go允许你创建紧凑的数据结构,避免不必要的重定向。
- 紧凑的数据结构可以更好的利用cache。
- 更好的cache利用率带来更好的性能。
inlining
函数调用的时候会发生3件事:
- 一个新的栈将被创建,调用者的详细信息被记录。
- 任何可能在调用过程中被覆盖的寄存器都将被保存到栈中。
- 处理器计算被调用函数的地址,然后在这个新的地址上开始执行新的分枝。
** 函数调用会带来不可避免的开销。**
由于函数调用是非常常见的操作,所以CPU设计者非常努力的优化这个流程,但是他们不能消除这个开销。基于函数所做的事情不同,这些开销可能是微不足道的,也可能是非常重要的。
一个减少函数调用开销的方案是一个叫做inlining的优化技术。
Go编译器将函数的主体内联到调用位置,作为调用者的一部分。** inlining也是有代价的,它增加了二进制文件的大小。**
只有当函数调用的开销占用函数实际执行的很大比例的时候进行内联才有意义。所以简单的函数适合被内联。复杂的函数常常不被调用它们的开销所主导,所以不需要被内联。
inlining sample:
package util
//Max returns the larger of a or b
func Max(a, b int) int {
if a > b {
return a
}
return b
}
------------------------------------------------------
package main
import "util"
//Double returns twice the value of the larger of a or b
func Double(a, b int) int {
return 2 * util.Max(a, b)
}
在这个示例中函数Double将调用util.Max
为了降低调用util.Max的开销,编译器可以将util.Max内联到Double中。效果类似于下面这个样子:
func Double(a, b int) int {
temp := b
if a > b {
temp = a
}
return 2 * temp
}
内联后不在需要调用util.Max,但是Double的行为不会发生改变。
inlining并不是Go独有的,几乎所有的编译型语言都会执行这样的优化。Go的inlining是如何工作的呢?
Go的实现非常简单。编译的时候,任何符合内联的小函数都将先被标记,然后再正常编译。然后函数的源代码和编译后的版本都将被保存。
下面这张图显示了编译后的util.a的内容,源代码稍微做了一些转换以方便编译器能快速的处理。它可以使用源代码中的函数,而不是插入一个对util.Max的编译版本的调用。

拥有函数的源,还是可以实现其他的优化。比如,死代码消除(Dead code eliminate)
func Test() bool { return false }
func Expensive() {
if Test() {
//something expensive
}
}
这个示例中,尽管Test函数总是返回false,但是Expensive在不执行它的情况下,并不能知道这个情况。当inlining被内联后,我们将得到类似于下面的代码:
func Expensive() {
if false {
//something expensive is now unreachable
}
}
编译器就知道了expensive这段代码现在是不可达的了。这不仅仅节省了调用Test的开销,它还节省了任何编译和运行expensive的开销,因为现在它是不可达的了。
Escape Analysis
强制垃圾回收,使得Go成为一门更简单、更安全的语言。但是这并不意味着垃圾回收会让Go变慢,也不意味着垃圾回收是决定你程序速度的终极原因。
它仅仅意味着在堆(heap)上分配内存是有代价的。每一次从GC开始运行直到内存被从堆中释放,都是一次会耗费CPU时间的债务。

除了从堆上分配内存外,还有另外一个地方可以分配内存,就栈。
C语言会强制你选择一个值是存储在堆上还是栈上(通过malloc的方式,值将从堆获取内存空间,或者在函数内声明的局部变量将被存储在栈上)。同C语言不同,Go实现了一种叫Escape Analysis的优化方法。
Escape Analysis
- Escape Analysis判断任何对在一个函数内声明的变量的引用是否会逃出函数范围。
- 如果没有引用逃出,那么这个值可以安全的存储在栈上。
- 存储在栈中的值不需要执行alloc分配空间,也不需要额外的free操纵。
来看下示例:
//Sum returns the sum of the numbers 1 to 100.
func Sum() int {
numbers := make([]int, 100)
for i := range numbers {
numbers[i] = i + 1
}
var sum int
for _, i := range numbers {
sum += i
}
return sum
}
这个示例中Sum计算了从1到100所有数之和,并返回结果。虽然这个实现有点奇葩,但是这是一个很好的例子说明Escape Analysis是如何工作的。
因为numbers数组只在Sum函数内被引用,编译器只会安排将它存储在栈中,而不是从堆中分配存储空间。所以也没有必要对numbers进行垃圾回收,它在Sum函数返回时将会自动被回收。
再来看一个示例:
const Width, Height = 640, 480
type Cursor struct {
X, Y int
}
func Center (c *Cursor) {
c.X += Width/2
c.Y += Height/2
}
func CenterCursor() {
c := new(Cursor)
Center(c)
fmt.Println(c.X, c.Y)
}
这个示例的实现同样有点怪怪的,在CenterCursor中,我们创建一个新的Cursor对象,然后将它的指针赋值给变量c。然后我们将C传给函数Center,Center将光标移到屏幕的中央。最后我们打印了光标X、Y的值。
虽然变量c是使用new分配的空间,但是它仍然不会被存储在堆上,因为没有对c的引用会逃离函数CenterCursor。

Go默认情况下优化总是打开的。你可以通过指定-gcflags=-m选项查看编译器的Escape Analysis和inlining决定。
因为escape analysis是在编译时而不是运行时执行的,stack空间的分配总是比堆空间的分配更快,不管你的垃圾回收效率有多高。
接下来的部分,我们还将更多的讨论到栈。
Goroutines
Goroutines是Go并发的基础。让我们稍微回顾一下历史,探讨下带领我们到Goroutines的历史。
在刚开始有计算机的时候,一次只能运行一个进程。然后到了60’s年代,多进程,或者可以叫做分时复用变得流行起来了。
在一个分时复用系统中,操作系统必须通过记录当前运行进程的状态,然后恢复另一个进程的状态来在进程之间不停切换CPU执行不同的进程。这个叫做进程切换。
进程切换的代价
进程切换有三个主要的代价:
-
存储和恢复所有的CPU寄存器。
首先内核需要存储当前运行的进程的所有CPU寄存器,然后再恢复另一个进程的所有寄存器。
-
重新配置内存管理单元。
内核还需要刷新CPU中实际内存到到虚拟内存的映射,因为当前的映射只对当前的映射有效。
-
切换到内核空间和调度器开销。
最后操作系统上下文的切换,以及调度器选择下个执行的进程都需要开销。
Processor Registers

现代处理器有数量让你感觉到惊讶的寄存器数量。把它们都列出来有点困难。这里列出来的只是给你一个直观的感受,存储和恢复它们需要花费多少时间。
因为进程的切换可能发生在一个进程执行的任何点。操作系统需要存储所有这些寄存器的内容,因为它根本不可能知道哪些当前在使用。
Threads
- 线程之间共享内存空间。
- 相比于独立的进程,可以更快的创建和切换线程。
线程开发的概念上同进程相同,只是线程之间共享内存空间。这使得线程的创建和切换都更快。
Goroutines
- Goroutines的调度是相互协调的。
- 因为协调调度,Goroutines之间的切换只会发生在一些良好定义的点。
- 所以编译器知道切换时哪些寄存器正在被使用,然后能够自动的保存它们。
Goroutines进一步扩展了线程的思想。Goroutines是协调调度的,而不是依赖内核来管理它的分时系统。对Goroutines的切换只会发生在对Go运行时调度程序(go)显示调用的一些良好定义的点上。所以编译器能够知道哪些寄存器正在被使用,而能够自动的存储这些寄存器值。
Goroutines调度发生的点:
- Channel sending and receiving
- go声明
go func() {}(), 但是并不能保证一个新的Goroutine将被马上调用。 - Blocking syscall,比如文件和网络操作。
- Garbage collection
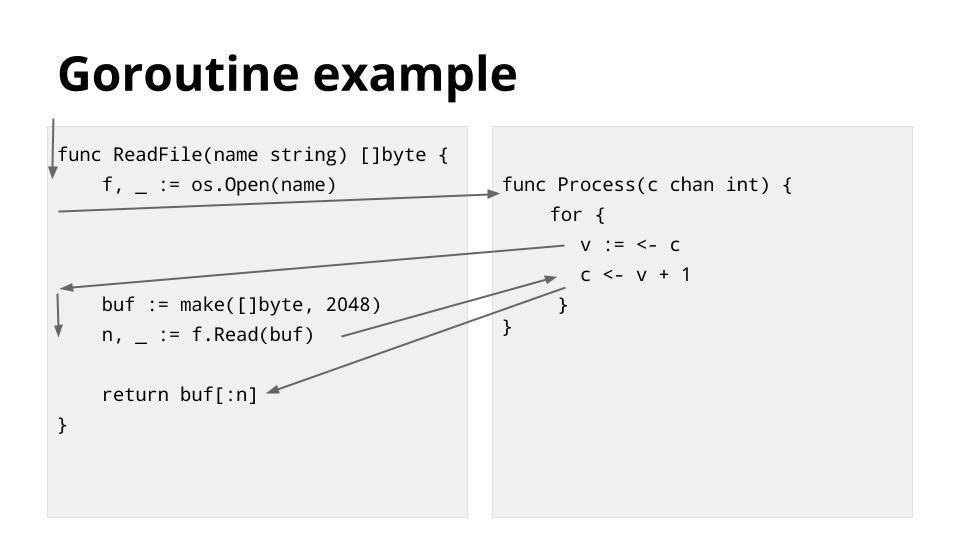
这个示例展示了前面描述的一个调度点。Thread沿着箭头的顺序,从左侧的ReadFile开始。然后遇到了os.Open,这将发生阻塞直到文件操作结束,所以调度器将这个线程切换到执行右边的Process函数。
CPU继续执行右边的程序,直到读取c channel发生阻塞,并且这时os.Open造成的阻塞已经结束,所以调度器继续将线程切回到左边继续执行,然后ReadFile又将在f.Read因为文件IO被阻塞。
这时右边的阻塞条件已经在左边执行时被解除了,调度器又将线程切换到右边继续执行,直到写channelc又发生阻塞。然后在左边的阻塞结束,数据可用时,调度器又将线程切回左边。执行完毕后再切回右边。

上图展示了runtime.Syscall函数的底层实现,这个函数是所有os包的函数的基础。任何时候你的代码需要执行一次系统调用时,都会经过这个函数。
对entersyscall的调用会通知runtime这个线程将要被阻塞了。这允许runtime启动一个新线程,这个新线程将在这个线程被阻塞时为其他线程服务。**Go的runtime会考虑将一个可运行的Goroutines分配到一个空闲的操作系统线程,这就造就了每个Go进程只有很少的几个线程。
Segmented and copying stacks
前面我们讨论了Goroutines是如果降低了管理成千上万个并发线程的开销的。这一节我们将继续讲Goroutines的故事,这是有关栈管理的。
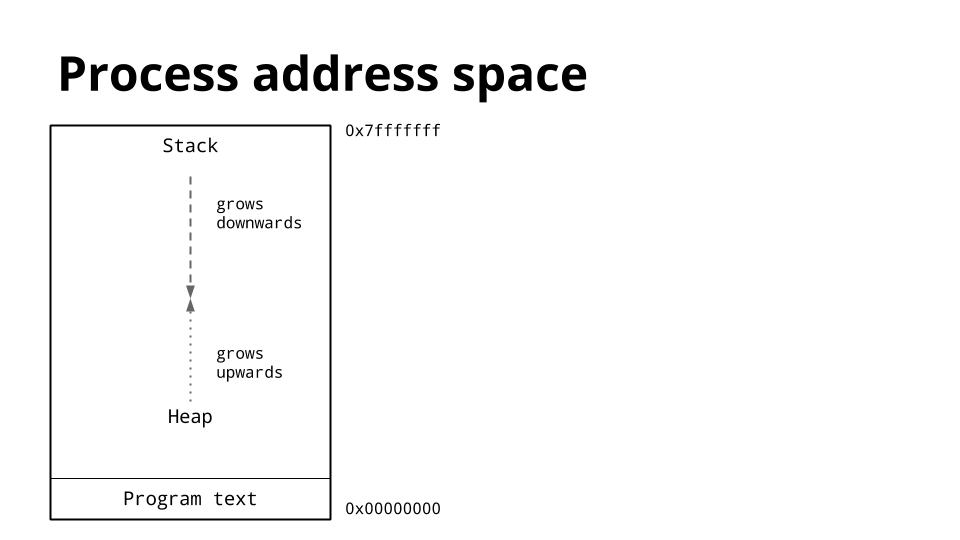
这张图暂时了一个进程的内存布局,我们关注的重点的堆和栈的位置。
传统上,在一个进程的地址空间内,堆空间位于内存的底部只是在text段上面,然后是向上增长的。栈则是位于虚拟地址空间的顶部,然后是向下增长的。
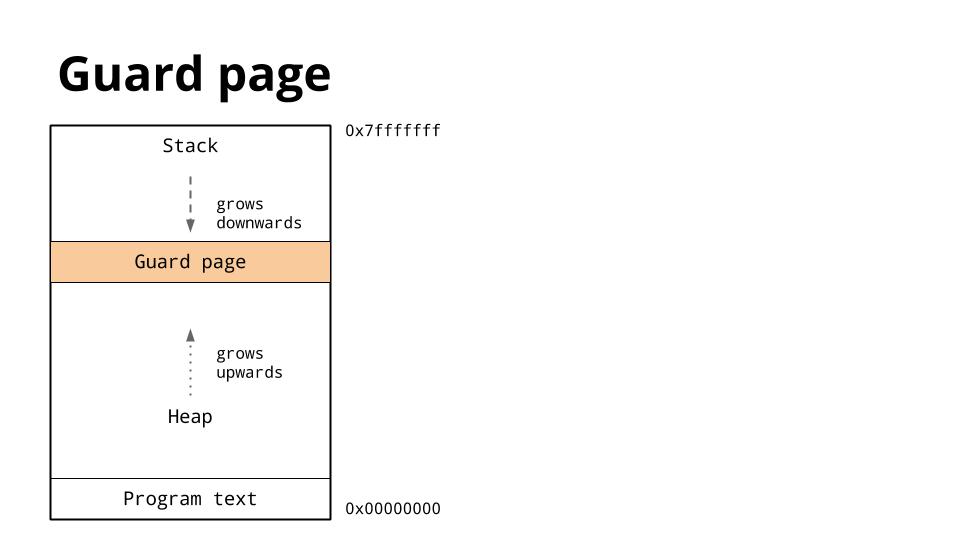
由于堆和栈相互覆盖可能会造成非常严重的后果,操作系统通常在堆和栈之间之前分配一段不可写的内存区域用于确保它们不会有冲突造成程序退出。这个称作guard page,它有效的限制了栈空间的大小,通常是几M的数量级(使用ulimit可以查看,通常Linux默认是8M)。
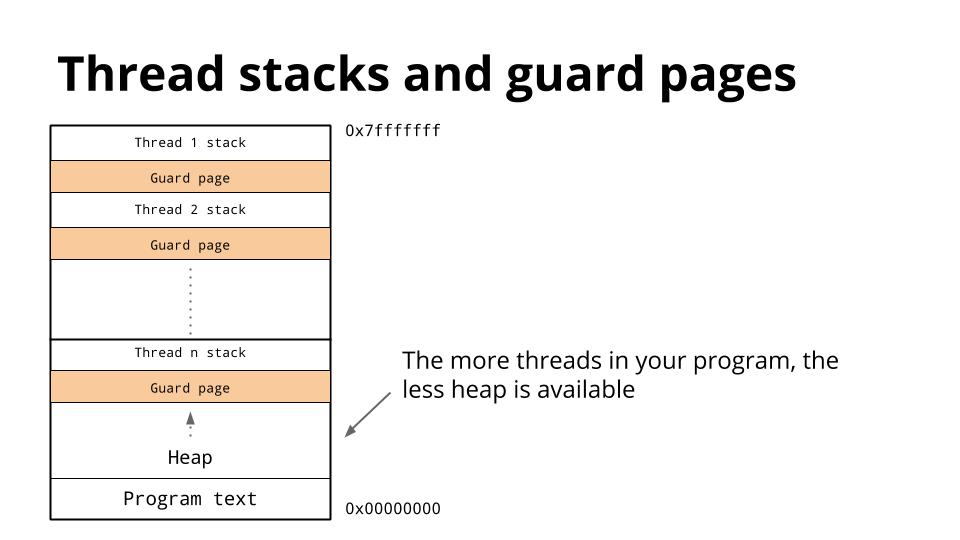
前面我们已经讨论了线程共享地址空间,所以对于每一个线程它必须有自己的栈空间。因为很难预测一个特定的线程需要的栈空间的大小,大量的地址空间被预留给每个线程的栈已经一个紧随的guard page。期望的就是这些预留的栈空间被实际需要的要大,而且guard page永远不会被击中。缺点就是,随着你线程数量的增加,可用的地址空间越来越小。
Goroutine stacks
我们已经看到了Go的runtime调度了大量的Goroutines到很少的几个线程上,那么Goroutines的栈需求是什么样的呢?
Go的编译器不使用guard pages,而是将检查作为每一个函数调用的一部分进行插入,以检查是否有足够的栈用于函数调用。如果没有,则runtime分配更多的栈空间。
由于有了这个检查,Goroutine的初始栈可以做得非常小,这又允许了程序猿能够把Goroutines当做廉价资源对待。
总结下,Goroutines Stacks的特性如下:
- No gurad pages
- Check for available stack space is done as part of the function call
- initial stack size very small, currently 8KB
- Grows as needed
Segmented Stacks
.jpg)
这张图展示了Go1.2中栈是如何被管理的。当G调用H时,没有足够的空间供H运行,所以runtime从堆上分配了一段新的栈帧,然后在这个新的栈segment上运行H。在H返回时,这段栈空间将在运行G前被释放然后还给堆。
通常情况下,这种栈管理方法运行得很好。但是对于某种特定类型的代码,多半是递归代码,它会造成你程序的内部循环频繁的跨越栈边界。
例如下面这段代码:
func G(items []string) {
for item := range items {
H(item)
}
}
这段代码中,函数G的内部循环会多次调用函数H。如上图所示,调用H时没有足够的栈空间,就会造成每次调用都会有stack split。这就是已知的hot split问题。
.jpg)
为了解决hot split问题,Go1.3开始采用新的栈管理方法。如果goroutine的栈空间太小,新的管理方法不会增加和移除新的栈segment,而是会分配一个新的更大的栈。然后旧栈空间的内容将被拷贝到新的栈空间,然后Goroutine在新的更大的栈空间上运行。
所以如上图所示,第一次调用H时,一个更大的栈被分配,然后发生Copying stacks,然后其他对H调用所以的栈空间检查都会返回成功,不需要再进行额外的栈split操作。
总结
Values, inlining, Escape Analysis, Goroutines and Segmented/Copying stacks这是今天我选出来讲的5个特征,但这并不意味着就只有它们是使得Go更快的特征。就像有很多原因会促成大家学些Go,但是排前面的是那三个一样。
虽然这个5个特征每一个都很强大,但是它们也不是独立存在的。例如,没有可增长个栈,runtime将Goroutines复用到threads上的方法也不会这么有效。inlining通过将小函数合并到大函数中,减少了栈空间检查的开销。Escape Analysis通过自动的将向堆申请的空间从栈上分配减少了Garbage collector的压力。Escape Analysis还提供了更好的cache能力。但是在没有可增长的栈的情况下,Escape Analysis则可能会给栈更大的压力。