[译]城里来的新孩子——Go的sync.Map
Go 1.9 release把并发map加人到标准库里面了,就是sync包下面的Map(sync.Map)。最近本来想一篇介绍它怎么使用,以及在它之前使用sync.Mutex或sync.RWMutex加传统的map实现map的并发读写的不同的文章。但是写之前,搜了一把是否有人已经做过类似的工作了,然后就发现了这个叫Ralph Caraveo的哥们儿已经写了这一篇。而且这篇文章不仅介绍了sync.Map怎么使用,还是介绍了它的设计原因,以及设计目标。还有一个各种使用场景下跟原来的map加sync.RWMutex性能比较的benchmark测试。所以我也没有必要再重新写一篇,他这篇文章已经远超了我想写的东西了,就直接翻译过来分享给大家吧。再多说一句,这哥们儿有很多不错的关于Go的博客,大家可以直接去他那里看原文。我也还有翻译一些他的其他文章,改天校验一遍再po出来吧。
原文地址:The new kid in town — Go’s sync.Map
对Go1.9中新加入的类型sync.Map的学习和探索性分析。
Go1.9出来后,我就迫不及待的开始尝试接触sync包中新加入的sync.Map容器了。首先,为什么要将它加入到标准库中?它又应该在哪里使用?不幸的是,答案是:除非遇到后面两种情况你真的不需要使用它。a). 你已经在使用常规的类型安全的map的应用程序中发现了瓶颈;b). 你的用例同新的sync.Map设计用于的目标用例匹配。
让我们更实际点。如果你没有首先确定和测试基于常规的map类型的实现已经遇到了竞争的问题,你就直接开始使用sync.Map,你可能会遇到些头痛的问题,然后越来越严重,嗯!当你使用新的并发实现(sync.Map)时,有一些保护机制可能就没有了。
首先,很明显的你会失去类型安全。我虽然并不了解你,但是基于Go标准库提供的有限的数据库集合,对于任何的基于key/value的数据你的选择显然首先是內建的基础map。我们不能期望一个不是简单且通用的数据结构(sync.Map)为我们提供类型完全。
另外,如果你读了新的sync.Map的迭代函数——Range的文档,你可能会注意到关于一致性快照的额外保护也被Range舍弃了。
Map.Range Range does not necessarily correspond to any consistent snapshot of the Map’s contents
另一个确定就是——你可能会牺牲性能?在很多情况下,内置map的现有实现的性能已经足够的好,并且在每个时间单元完成的操作上多次击败sync.Map的实现。事实上,如果你能够在不使用锁的情况下使用内置的map,那么你已经掌握了胜利的武器。
但是我们会因为一个原因使用锁:大多数人应该知道内置的地图有个不好的小秘密。如果多个Goroutines对同一个map执行读或写,map并不是线程安全(或者说并发安全)的。这也是为什么标准库以同步原语的形式提供了一些工具来处理这种情况。你可以使用channel,mutex,r/w mutex以及原子操作。
并且基于你的使用情况,在你的生产代码中使用其中的一种或两种并不罕见,这样你就可以充分享受没有数据竞争的代码了。你将使用哪种工具并不在本文的讨论范围之内,让我们回到内置的map上来。当这个数据结构需要面对并发的数据更新时应该怎么办?
在写代码之前,我会非常仔细的选择我所要使用的同步原语,你也应该要这样。首先,如果我不共享任何状态,那么我可以完全避免使用同步原语来写代码,因为我已经选择了一个不需要共享状态的架构。这通常是一个理想情况,但是是一个不可实现的梦想。
任何复杂的代码通常都会陷入到的一个瓶颈就是代码之间需要交互或者同步,这就是现实,除非你生活在一个完全纯净的世界中。到此,有一种常见的习惯用法就是将一个内置的map与一种同步机制打包在一个小的包裹之内。在这种情况下,你多半都是使用sync.Mutex来对map做出改变。它将为你提供必要的锁定来保护内置map免受并发更新。
但是在你想要读一个map的时候,使用sync.Mutex的问题就会出现。不管是你是想知道map的大小,或者简单的迭代map,还是只是想检查一个数据是否在map中存在,所有这些都是读操作。技术上讲,这些读操作是可以与其他不会做出改变的读操作一起发生的。但是使用synx.Mutex这些操作也会被同写数据一样无差别对待,被锁定。
然后Go又很贴心的提供了sync.RWMutex。它提供的条件是:你所有的读操作需要承诺一个读锁——RLock来保证这些操作不会改变map的数据。反过来,所有需要改变map内容的写操作则需要使用常规的写锁——Lock,这样就可以保证在更新时候的排他性。
sync.RWMutex的好处就是,在高并发读取场景下可以减少锁的竞争。至少,设计它的初衷是这样的… …
下面是一个将内置map和sync.RWMutex在一起封装成类似于sync.Map的API的示例:
package RegularIntMap
type RegularIntMap struct {
sync.RWMutex
internal map[int]int
}
func NewRegularIntMap() *RegularIntMap {
return &RegularIntMap{
internal: make(map[int]int),
}
}
func (rm *RegularIntMap) Load(key int) (value int, ok bool) {
rm.RLock()
result, ok := rm.internal[key]
rm.RUnlock()
return result, ok
}
func (rm *RegularIntMap) Delete(key int) {
rm.Lock()
delete(rm.internal, key)
rm.Unlock()
}
func (rm *RegularIntMap) Store(key, value int) {
rm.Lock()
rm.internal[key] = value
rm.Unlock()
}
注意,上面的这段代码中Load只是一个接收方法,它不会改变map的任何数据。这一点很重要,因为这样Load就可以无限制的使用读锁,然后多个Goroutines可以并发的执行它了。
但是,在对标准库做了额外的审查和性能分析之后,很多Go团队成员发现当使用sync.RWMutex的代码被部署在有很多、很多核的CPU上的时候,它的性能远低于理想值。对于这里提到的“很多”,我并不是在说你的典型的8核或者16核的系统,重要的是那些系统配置可能远超这个。在这些地方CPU的核数能够呈现出代码的高度竞争性,就像使用sync.RWMutex一样。
现在我们已经基本明了为什么会创建一个新的Sync.Map了。Go团队确认了一个标准库的性能不佳的情况。在部署在一个有很多CPU核的系统上的高读取场景下,从使用sync.RWMutex封装的数据结构中读取数据的性能会受到很大影响。
事实上,在2017 GopherCon有一个闪电演讲:An overview of sync.Map介绍了关于sync.Map诞生的原因以及它的设计目标。如果你在考虑使用这个实现,建议你一定要看下这个视频,视屏中讲解了它可能有的一些性能陷阱。
通过下面这段代码,让我们看看sync.Map是如何使用的:
func syncMapUsage() {
fmt.Println("sync.Map test (Go 1.9+ only)")
fmt.Println("----------------------------")
// Create the threadsafe map.
var sm sync.Map
// Fetch an item that doesn't exist yet.
result, ok := sm.Load("hello")
if ok {
fmt.Println(result.(string))
} else {
fmt.Println("value not found for key: `hello`")
}
// Store an item in the map.
sm.Store("hello", "world")
fmt.Println("added value: `world` for key: `hello`")
// Fetch the item we just stored.
result, ok = sm.Load("hello")
if ok {
fmt.Printf("result: `%s` found for key: `hello`\n", result.(string))
}
fmt.Println("---------------------------")
}
注意API与内置map的使用方式的明显不同。另外,由于sync.Map并不是类型安全的,所以我们在使用Load读取数据的时候我们需要做类型转换。类型转换可能会成功也可能会失败,需要小心。(注:类型转换失败,通常会造成程序panic,所以最好使用类型断言。)
除了Load和Store方法外,我们还有Delete, LoadOrStore以及Range方法。读者可以自己练习来学习和使用这些方法。
那么sync.Map是如何执行的呢?
目前我的性能分析还正在进行当中。我还只是刚刚开始分析这个事情,尽我所能写正确的benchmarks来模拟不同的场景。此外,我还在尝试寻找这个新容器的设计目标场景,以期证明它的理想场景的最好性能。
它的性能特征的文档是像下面这样描述的:
它针对keys长时间没有变化且只有很少的稳态存储的,或者每一个Goroutine中有一个本地存储的key的并发循环使用做了优化。
对于不共享这些属性的使用场景,使用它同与使用
sys.RWMutex保护的内置map相比可能有更差的性能表现,以及更差的类型安全。
所以如我在前面理解的,如果我使用内置map显示出了数据竞争迹象同时map的key在整个应用程序的生命周期内不会经常变换,我可能会考虑使用sync.Map。对我来说,通俗的讲这个就是一个只有少量更新的高并发读取场景,或者只在一些突发情况下会发生大规模更新的场景。
第一个benchmark显示了使用与sync.RWMutex一起的常规map与sync.Map之间写数据的比较:
func nrand(n int) []int {
i := make([]int, n)
for ind := range i {
i[ind] = rand.Int()
}
return i
}
func BenchmarkStoreRegular(b *testing.B) {
nums := nrand(b.N)
rm := NewRegularIntMap()
b.ResetTimer()
for _, v := range nums {
rm.Store(v, v)
}
}
func BenchmarkStoreSync(b *testing.B) {
nums := nrand(b.N)
var sm sync.Map
b.ResetTimer()
for _, v := range nums {
sm.Store(v, v)
}
}
/*
BenchmarkStoreRegular-32 5000000 319 ns/op
BenchmarkStoreSync-32 1000000 1146 ns/op
*/
下面是删除操作的benchmark:
func BenchmarkDeleteRegular(b *testing.B) {
nums := nrand(b.N)
rm := NewRegularIntMap()
for _, v := range nums {
rm.Store(v, v)
}
b.ResetTimer()
for _, v := range nums {
rm.Delete(v)
}
}
func BenchmarkDeleteSync(b *testing.B) {
nums := nrand(b.N)
var sm sync.Map
for _, v := range nums {
sm.Store(v, v)
}
b.ResetTimer()
for _, v := range nums {
sm.Delete(v)
}
}
/*
BenchmarkDeleteRegular-32 10000000 238 ns/op
BenchmarkDeleteSync-32 5000000 393 ns/op
*/
下面是读数据的benchmark,其中叫Found用例总是能够从map中读取到数据,叫NotFound的用例则几乎总是读取不到数据。
func BenchmarkLoadRegularFound(b *testing.B) {
nums := nrand(b.N)
rm := NewRegularIntMap()
for _, v := range nums {
rm.Store(v, v)
}
currentResult := 0
b.ResetTimer()
for i := 0; i < b.N; i++ {
currentResult, _ = rm.Load(nums[i])
}
globalResult = currentResult
}
func BenchmarkLoadRegularNotFound(b *testing.B) {
nums := nrand(b.N)
rm := NewRegularIntMap()
for _, v := range nums {
rm.Store(v, v)
}
currentResult := 0
b.ResetTimer()
for i := 0; i < b.N; i++ {
currentResult, _ = rm.Load(i)
}
globalResult = currentResult
}
func BenchmarkLoadSyncFound(b *testing.B) {
nums := nrand(b.N)
var sm sync.Map
for _, v := range nums {
sm.Store(v, v)
}
currentResult := 0
b.ResetTimer()
for i := 0; i < b.N; i++ {
r, ok := sm.Load(nums[i])
if ok {
currentResult = r.(int)
}
}
globalResult = currentResult
}
func BenchmarkLoadSyncNotFound(b *testing.B) {
nums := nrand(b.N)
var sm sync.Map
for _, v := range nums {
sm.Store(v, v)
}
currentResult := 0
b.ResetTimer()
for i := 0; i < b.N; i++ {
r, ok := sm.Load(i)
if ok {
currentResult = r.(int)
}
}
globalResult = currentResult
}
/*
BenchmarkLoadRegularFound-32 10000000 180 ns/op
BenchmarkLoadRegularNotFound-32 20000000 107 ns/op
BenchmarkLoadSyncFound-32 10000000 200 ns/op
BenchmarkLoadSyncNotFound-32 20000000 291 ns/op
*/
正如你所看到的,这些benchmark中的所有用例中使用sync.RWMutex保护的常规map的性能都远胜于sync.Map。并且到目前为止,我们还没有将benchmark引入到多个goroutines中。让我们继续讨论这个问题,让我们看看夸核扩展成为一个因子后设计的benchmark性能如何。
让我们来使用Digital Ocean上的一个32核的虚拟机看看趋势是怎么样的。为此我在San Francisco创建了一个虚拟机运行Ubuntu 16.04.3 (x64),并且我选了他们有的最贵的虚拟机,这台机器每个月要$640。对于我来说,运行这些benchmarks只花了大概两个小时可能只值几块钱吧。这不是一个Digital Ocean的广告,但是我觉得他们的栈还是不错的,而且他们还在内部使用Go,所以就顺便帮他们打一下广告吧。
对于这个benchmark,我想在当前的理想场景下测量基于两种map的实现的性能。在这个场景下,我将构建存储一组随机数据的两中map,并且我将在每个benchmark中使用不同的** GOMAXPROCS**并且创建与GOMAXPROCS数量相同的goroutines来执行。
再次,我将运行这些测试来模拟一个高读取场景,所以在benchmark时钟开始之前map内容就已经被构建并固定了。在这篇的文章的下一次更新中,我可能会创建一个benchmark来模拟固定数量的写入,但是现在让我们考虑这个有点人造的但是理想的用例。
接下来是我将如何定义这些并发的benmarks,但是首先概要的说明下代码:
这些benchmarks实际是一些被其他函数调用的函数,在调用函数中我们写死了workerCount。这样我们就能为每个benchmark配置GOMAXPROCS和workers的数量。
确保我们不会遇到Go编译器的优化,我们捕获了Load方法的输出。我们并不关心Load的结果,只是确保编译器不会因为我们未使用输出结果而将代码判断为死代码并将这段代码移除。
代码的主要部分将启动一个goroutine作为worker,它将通过使用b.N值来尽可能的的迭代满足Go benchmark的条件。随着每个goroutines的运行,我们执行我们的Load操作,最后使用sync.WaitGroup来通知goroutine的结束。
func benchmarkRegularStableKeys(b *testing.B, workerCount int) {
runtime.GOMAXPROCS(workerCount)
rm := NewRegularIntMap()
populateMap(b.N, rm)
var wg sync.WaitGroup
wg.Add(workerCount)
// Holds our final results, to prevent compiler optimizations.
globalResultChan = make(chan int, workerCount)
b.ResetTimer()
for wc := 0; wc < workerCount; wc++ {
go func(n int) {
currentResult := 0
for i := 0; i < n; i++ {
currentResult, _ = rm.Load(5)
}
globalResultChan <- currentResult
wg.Done()
}(b.N)
}
wg.Wait()
}
func benchmarkSyncStableKeys(b *testing.B, workerCount int) {
runtime.GOMAXPROCS(workerCount)
var sm sync.Map
populateSyncMap(b.N, &sm)
var wg sync.WaitGroup
wg.Add(workerCount)
// Holds our final results, to prevent compiler optimizations.
globalResultChan = make(chan int, workerCount)
b.ResetTimer()
for wc := 0; wc < workerCount; wc++ {
go func(n int) {
currentResult := 0
for i := 0; i < n; i++ {
r, ok := sm.Load(5)
if ok {
currentResult = r.(int)
}
}
globalResultChan <- currentResult
wg.Done()
}(b.N)
}
wg.Wait()
}
func benchmarkRegularStableKeysFound(b *testing.B, workerCount int) {
runtime.GOMAXPROCS(workerCount)
rm := NewRegularIntMap()
values := populateMap(b.N, rm)
var wg sync.WaitGroup
wg.Add(workerCount)
// Holds our final results, to prevent compiler optimizations.
globalResultChan = make(chan int, workerCount)
b.ResetTimer()
for wc := 0; wc < workerCount; wc++ {
go func(n int) {
currentResult := 0
for i := 0; i < n; i++ {
currentResult, _ = rm.Load(values[i])
}
globalResultChan <- currentResult
wg.Done()
}(b.N)
}
wg.Wait()
}
func benchmarkSyncStableKeysFound(b *testing.B, workerCount int) {
runtime.GOMAXPROCS(workerCount)
var sm sync.Map
values := populateSyncMap(b.N, &sm)
var wg sync.WaitGroup
wg.Add(workerCount)
// Holds our final results, to prevent compiler optimizations.
globalResultChan = make(chan int, workerCount)
b.ResetTimer()
for wc := 0; wc < workerCount; wc++ {
go func(n int) {
currentResult := 0
for i := 0; i < n; i++ {
r, ok := sm.Load(values[i])
if ok {
currentResult = r.(int)
}
}
globalResultChan <- currentResult
wg.Done()
}(b.N)
}
wg.Wait()
}
/*
// These tests do a lookup using a literal value.
// Regular Map backed by RWMutex
BenchmarkRegularStableKeys1-32 50000000 30.5 ns/op
BenchmarkRegularStableKeys2-32 10000000 157 ns/op
BenchmarkRegularStableKeys4-32 5000000 377 ns/op
BenchmarkRegularStableKeys8-32 2000000 701 ns/op
BenchmarkRegularStableKeys16-32 1000000 1446 ns/op
BenchmarkRegularStableKeys32-32 500000 2825 ns/op
BenchmarkRegularStableKeys64-32 200000 5699 ns/op
// Sync Map
BenchmarkSyncStableKeys1-32 20000000 89.3 ns/op
BenchmarkSyncStableKeys2-32 20000000 101 ns/op
BenchmarkSyncStableKeys4-32 5000000 247 ns/op
BenchmarkSyncStableKeys8-32 5000000 330 ns/op
BenchmarkSyncStableKeys16-32 5000000 295 ns/op
BenchmarkSyncStableKeys32-32 5000000 269 ns/op
BenchmarkSyncStableKeys64-32 5000000 249 ns/op
// These tests do a lookup of keys already defined in the map per iteration.
// Regular Map backed by RWMutex
BenchmarkRegularStableKeysFound1-32 20000000 114 ns/op
BenchmarkRegularStableKeysFound2-32 10000000 203 ns/op
BenchmarkRegularStableKeysFound4-32 3000000 460 ns/op
BenchmarkRegularStableKeysFound8-32 2000000 976 ns/op
BenchmarkRegularStableKeysFound16-32 1000000 1895 ns/op
BenchmarkRegularStableKeysFound32-32 300000 3620 ns/op
BenchmarkRegularStableKeysFound64-32 200000 6762 ns/op
// Sync Map
BenchmarkSyncStableKeysFound1-32 5000000 357 ns/op
BenchmarkSyncStableKeysFound2-32 3000000 446 ns/op
BenchmarkSyncStableKeysFound4-32 3000000 501 ns/op
BenchmarkSyncStableKeysFound8-32 3000000 576 ns/op
BenchmarkSyncStableKeysFound16-32 2000000 566 ns/op
BenchmarkSyncStableKeysFound32-32 3000000 527 ns/op
BenchmarkSyncStableKeysFound64-32 2000000 873 ns/op
*/
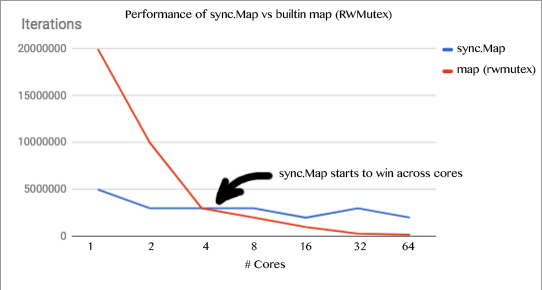
正如你所看到的,在使用sync.RWMutex保护的常规map上我们有很好的性能表现。事情一直沿着很好的方向在发展,但是到我们开始使用4核时情况就变了。在4核时,不仅数据竞争开始变成问题,就连我们夸核的扩展因子也是一个问题了。如果你是看的红线,当我们的CPU到8核的时候,你就可以忘了这根线了。在这个点上使用RWMutex我们有太多的读竞争,以至于到32核时性能受到很大影响。
蓝线表现的是sync.Map则展示了一个可预测的行为,因为我们持续的在扩展我们的核数。至此,我可以说基于我的初步测试和分析我们知道了sync.Map的发光点在哪儿。这个理想场景就是为它而建的。
那么sync.Map是如何实现这个性能的呢?嗯,这是另一篇博客文章的故事了,并且需要探索更多高级主题,例如以推理和可读性为代价的lock-free programming和atomic operations。我们后面可能会讨论这个,也可能不会,现在我还不太确定。
如果你已经看到这里了,你可能会对本文的benchmark有疑问或有建议来改进它。请在github上fork它或创建issuse来帮改进它。
我还有一些想分析的测试场景,对于这篇博文,我想从我理解的sync.Map设计的理想场景开始。无论如何,这都只是想要玩一下新的数据结构并且想学习更过关于它的知识的借口。
请留下你的反馈和意见,并记住在你想要使用sync.Map之前考虑是否过度使用。
“Premature optimization is the root of all evil.” — Donald Knuth
祝你Go编程愉快!